Datu analīze ar ChatGPT 4

Autors: Aivis Brutāns, datu zinātnieks un “Datu skolas” aktīvists
OpenAI ChatGPT nav tikai rīks, kurš piedāvā ar lietotāju čatot, bet tas ir mākslīgā intelekta asistents (AI assistent), kurš palīdz veidot attēlus, kā arī analizēt datus. Aplūkosim, cik labas ir OpenAI ChatGPT 4 sniegtās datu analītikas spējas.
Vispirms jāatzīmē, ka ChatGPT 4 šobrīd ir maksas pakalpojums, kas izmaksā 20 USD mēnesī (https://openai.com/chatgpt/pricing). Taču, ja lietotājs nevēlas, lai OpenAI izmanto viņa uzvednes (prompts) modeļu trenēšanā, tad ir jāiegulda vēl vairāk: jāpieslēdz biznesa klientu komplekts “Teams” par 25 USD/mēnesī no katra lietotāja (minimālais lietotāju skaits: 2).
Datu analīzē izmantots atvērto datu portālā publicēts vispārējās vidējās izglītības centralizēto eksāmenu (CE) rezultātu kopvērtējums un līmeņu sadalījums pa skolām par 2022./2023. mācību gadu. Uzvednes rakstītas angļu valodā.
ChatGPT 4 datu analīzē izmanto Python programmēšanas valodu, tāpēc papildu datu analīzes skaidrojumiem chat.openai.com rīkā atspoguļots arī šīs programmas kods.
“Perform an exploratory data analysis about these data”
Pirmajā uzvednē augšuplādēju .csv failu ar CE rezultātiem un prasu lai sagatavo datu analīzi (exploratory data analysis). Jau datu nolasīšanā ChatGPT saskārās ar problēmu — tas nevar nolasīt .csv failu.
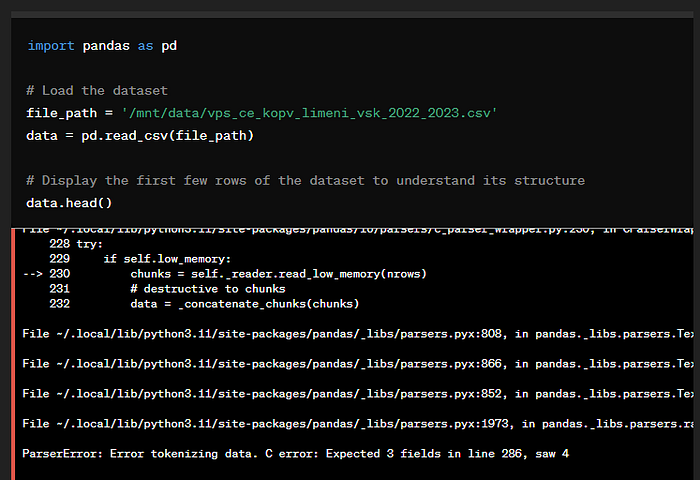
Rīks pats spēja atrast kļūdu — .csv failā kolonnu atdalītājs ir semikols (nevis komats), ChatGPT papildināja read_csv funkciju ar papildu parametru un faila datus nolasīt izdevās.

Pēc faila nolasīšanas rīks apraksta kādas kolonnas ir atspoguļotas failā:

Un datu analīzē piedāvā izpildīt sekojošus soļus:
- vispārīgu statistiku — vidējo eksāmenu vērtējumu un kārtotāju skaitu,
- kā sadalās vērtējumi un kārtotāju skaits starp dažādām pašvaldībām un izglītības iestādēm,
- trūkstošo vērtību apjoma novērtēšana un “izlecēju” (outliers) identificēšana,
- kāda ir tendence un saistība starp vidējo eksāmena vērtējumu un kārtotāju skaitu.

Vidē, kurā tiek darbināts Python kods, decimālskaitļa atdalītājs ir punkts, tāpēc ChatGPT automātiski pārveido kolonnas “Vidējais, %” vērtības — aizvietojot komatu ar punktu:
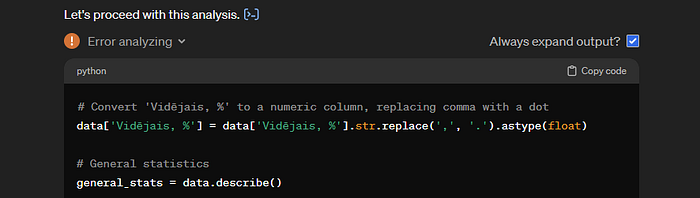
Taču rīks šeit saskārās ar kārtējo problēmu —kolonnā “Vidējais, %” ir ieraksts ar vērtību ‘#DIV/0!’ un, tādējādi, nevar šo vērtību pārvērst decimālskaitlī. Bet ar to viņš tiek galā, papildinot Python kodu, kas šādas vērtības aizvieto ar specifisku datu tipu NaN (not a number):
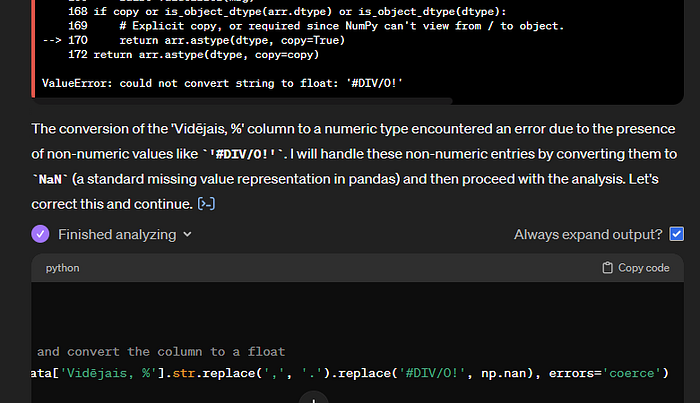
Rīks tālāk apraksta “Vidējais, %” un “Kārtotāju skaits” amplitūdas un vidējos rādītājus. ChatGPT nezina saistības starp šīm kolonnām, tāpēc “Vidējais, %” vidējo rezultātu aprēķina nepareizi — to vajag svērt ar kolonnas “Kārtotāju skaits” vērtībām:


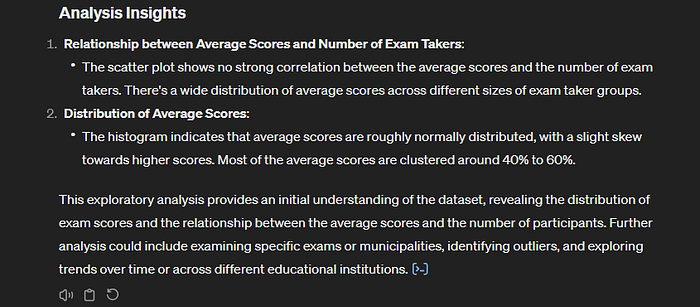
Lai redzētu sakarību starp kārtotāju skaitu un vidējo eksāmena vērtējumu, ChatGPT izveidoja grafikus. Jāņem vērā, ka viņš grafikā apkopojis informāciju par visu priekšmetu centralizētajiem eksāmeniem:

Arī izveidotajā histogrammā visi CE priekšmetu rezultāti atspoguļoti kopā:

Novēroju, ka nākamajā dienā grafiki vairs nav pieejami:

Pirmās uzvednes aprakstu ChatGPT noslēdz ar iepriekšējo grafiku skaidrojumu:
- nav stipras korelācijas starp vidējo CE rezultātu un eksāmenu kārtotāju skaitu,
- vidējais CE vērtējums ir normāli sadalīts ar nelielu asimetriju (skewness) uz augstāko vērtējumu pusi.
Tālāk rīks piedāvā analizēt jau konkrētus eksāmenus vai pašvaldības, identificēt “izlecējus” un trendu:
Rīks neizprot sakarības starp kolonnām, tāpēc korektai vidējā CE rezultāta aprēķināšanai turpmākajos soļos precizēts, ka šis rezultāts ir jāsver.
Prepare list of TOP 5 `Izsglītības iestādes nosaukums` which has a largest average `Vidējais, %` where `Pārbaudījums` LIKE `Eksāmens matemātikā%`. You need to weight average with `Kārtotāju skaits`
Frāze `Pārbaudījums` LIKE `Eksāmens matemātikā%` ir veidota SQL sintakses stilā, lai atlasītu visus gadījumus, kuros kolonnā “Pārbaudījums” vērtības sākas ar ‘Eksāmens matemātikā’. Šādu sintaksi norādīju uzvednē, cerot, ka tiks atlasīti visi iespējamie matemātikas eksāmenu pārbaudījuma veidi.
Rīks precīzi izpildīja komandu. Arī aprēķinā ir izmantots vidēji svērtais vidējais:
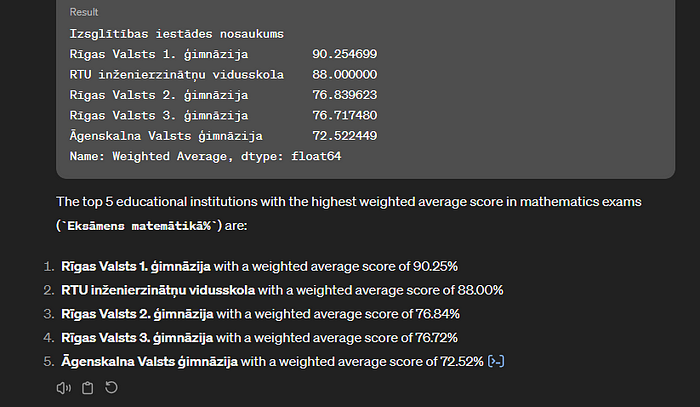
What about TOP 5 lowest scores?
Speciāli uzdevu šādu jautājumu, lai saprastu vai ChatGPT saprot, ka runa vēl joprojām ir par matemātikas CE. Saprata:
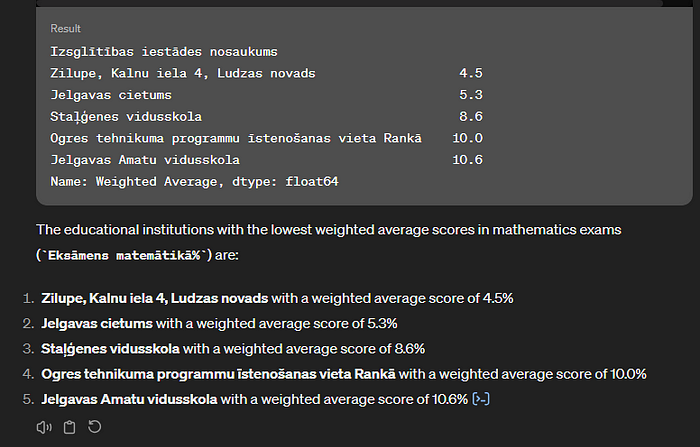
Why these schools has lowest scores in maths?
Provokatīvs jautājums, jo zinu, ka no datiem šo uzzināt nevar. Taču arī šeit ChatGPT nesamulst:


ChatGPT kā iespējamos zemo vērtējumus sasaista ar:
- mācību materiālu, personāla u.c. resursu trūkumu,
- izglītojamo sociālekonomisko stāvokli,
- atšķirīgu fokusu uz mācību priekšmetiem,
- izglītojamā iesaistes līmeni,
- atbalsta iespējām.
Lai saprastu precīzus zemā vērtējuma iemeslus, algoritms iesaka veikt papildu analīzi — intervijas, novērošanu, skolas politikas un prakses analīzi.
How strong is a correlation between maths scores and physics (`Pārbaudījums` like `Eksāmens fizikā%`) ?
Jāņem vērā, ka ne visās skolās tika kārtots gan matemātikas, gan fizikas CE. Tāpēc, atkarībā no datu apstrādes, var iegūt nepareizu rezultātu. Bet ar šo rīks tiek veiksmīgi galā —tas izmanto pandas merge funkciju, kur pēc noklusējuma datu savienošana ir pēc INNER JOIN principa.
Rezultātā tiek iegūts pareizs korelācijas koeficients:

Create a scatter plot with TOP 100 schools with highest scores in maths on x-axis and this schools’ scores in physics on y-axis. If school doesn’t have a score in physics then replace NaN with 0.
Šādu grafiku izveido bez problēmām:
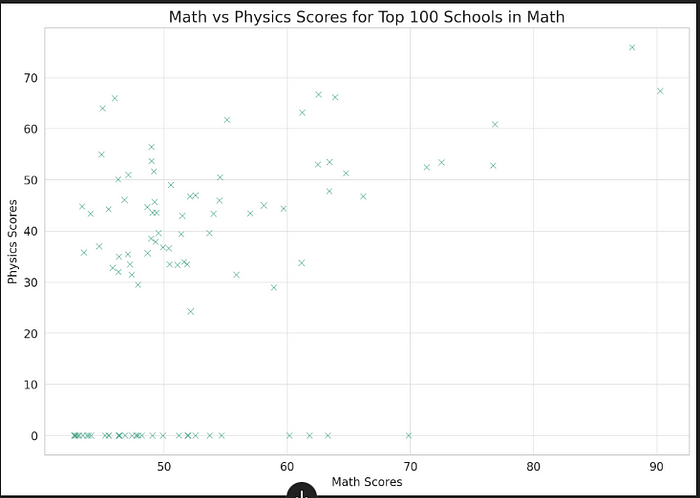
Pēc grafika redzam skolas, kurās matemātikas CE vērtējums ir lielāks par 60 un skolā izglītojamie nav kārtojuši fizikas centralizēto eksāmenu. Noskaidrosim kuras ir šīs skolas.
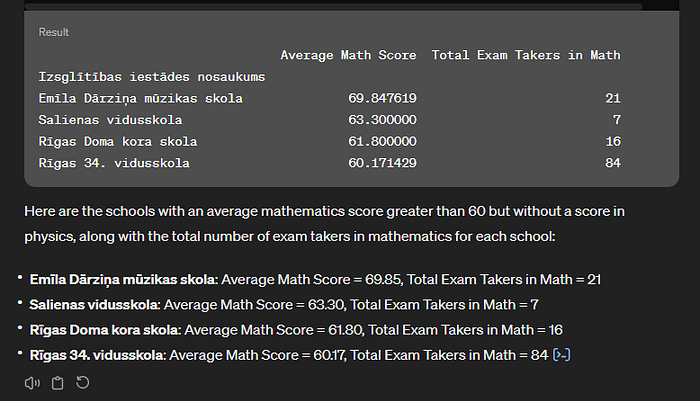
Give me a list of schools which has an average maths score greater than 60, but doesn’t have score in physics. Add sum of `Kārtotāju skaits` in maths for each school.
Pēc iepriekšējā grafika informācijas, rīkam ir jāatlasa 4 skolas. Tā arī notiek:
Create a choropleth map which shows average score in maths in `Pašvaldība` (Latvian cities and municipalities).
Rīkam nav pieejas Latvijas pilsētu un novadu robežu datiem, tāpēc tas kartogrammu nespēj izveidot:

Here are GeoJSON data.
Izmantoju citus atvērtos datus, kuros ir administratīvo teritoriju robežu dati GeoJSON formātā. Tā kā rīks nespējs lejuplādēt robežu datus pa tiešo (..since I cannot access external files or services to download the necessary geospatial data..), augšuplādēju datus un prasu sagatavot karti, bet ChatGPT pirmo reizi saskaras ar problēmu, ko nevar atrisināt:
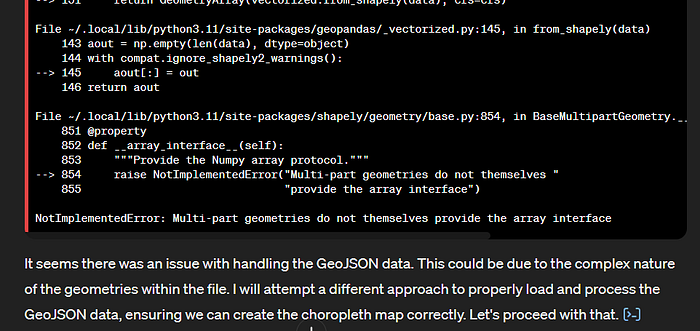

Rīks iesaka izmantot pēdējo versiju telpisko datu bibliotēkas (geospatial libraries). Pats ChatGPT savā vidē izmanto shapely pakotnes 1.7.1 versiju un iepriekš minētās kļūdas (“NotImplementedError: Multi-part geometries do not themselves provide the array interface”) atrisināšanai iesaka šo pakotni atjaunot, taču ChatGPT neparedz iespēju augšuplādēt Python pakotnes un tās aizvietot ar citām versijām.

Veicot visus tos pašus soļus uz lokālā datora, ar jaunāko shapely pakotnes versiju ir iespējams izveidot iepriekš prasīto kartogrammu (valstpilsētām neuzrādās dati, jo GeoJSON failā tie ir ar citādāku nosaukumu):

Uzdevu papildu jautājumus par datiem nākamajā dienā, bet ar to ChatGPT vairs netiek galā, jo ir beigusies sesija (laika intervāls, kurā ChatGPT apstrādā informāciju un sniedz atbildi uz lietotāja jautājumiem). Tas ir jāņem vērā veidojot datu analīzi. Varat rīkam likt apkopot visu iepriekš minēto Python kodu — pēc tam šo kodu izpildīt uz sava lokālā datora.
Kā ir ar latviešu valodu?
Vai ir iespējams visu iepriekš minēto analīzi prasīt latviešu valodā un visu vienā uzvednē? Jā ir:

Bet ir ļoti jāpiestrādā pie uzdevumu definēšanas, lai ChatGPT tos saprastu. Augstāk minētā uzvedne rakstīta ar otro piegājienu, taču rezultāts tāpat neatbilst prasītajam. Piemēram, šī uzdevuma “1) izveido vērtībamplitūdas diagrammu (box-whisker plot). Uz x-ass ir kolonnas PARB vērtības, uz y-ass ir “vidēji svērtais” eksāmena rezultāts. Katrs datu punkts norāda izglītības iestādes (`Izglītības iestādes nosaukums`) “vidēji svērto” vērtējumu.” sagaidāmais rezultāts:
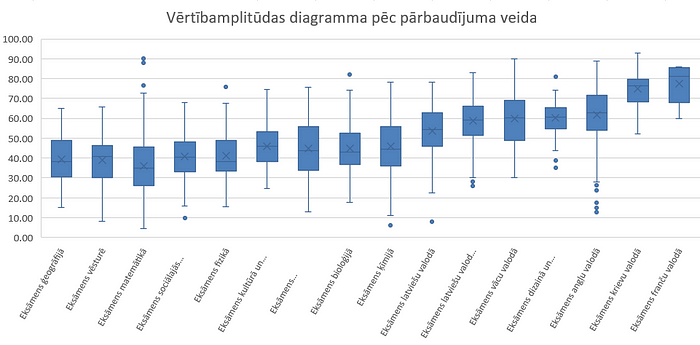
Bet ChatGPT sagatavoja grafiku tikai par četriem priekšmetiem (kas minēti uzdevuma 2.punktā un neattiecas uz 1.punktu):
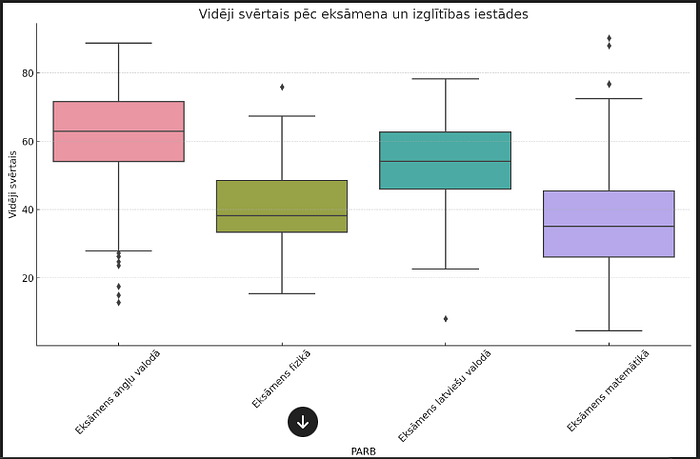
4.punkta sagaidāmais rezultāts — pašvaldība, kurai katrā pārbaudījumā ir sliktāks rezultāts nekā vidējais rādītājs valstī. Pēc šādiem kritērijiem atbilst tikai viena pašvaldība:
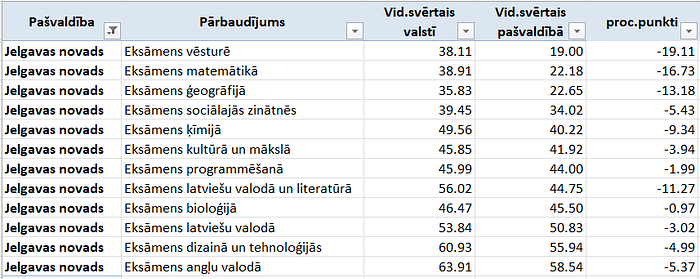
Taču ChatGPT sagatavoja statistiku atkal tikai par 2.punkta priekšmetiem un TOP 3 veidoja no pārbaudījumiem, nevis pašvaldībām. Kritērijs — “..katrā no PARB eksāmeniem ir sliktāks par atbilstošo PARB veidu valstī.” vispār netika ievērots:
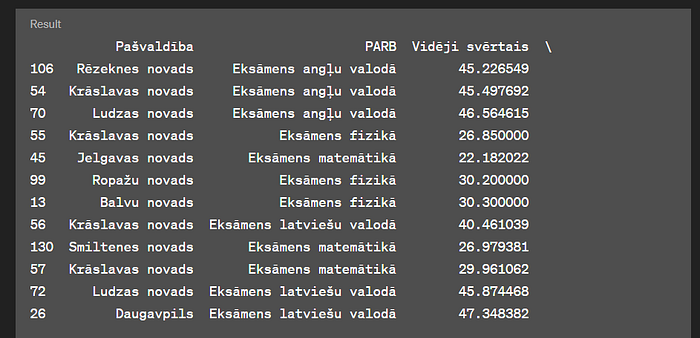
Tātad ieteicams veidot vairākas īsākas uzvednes.
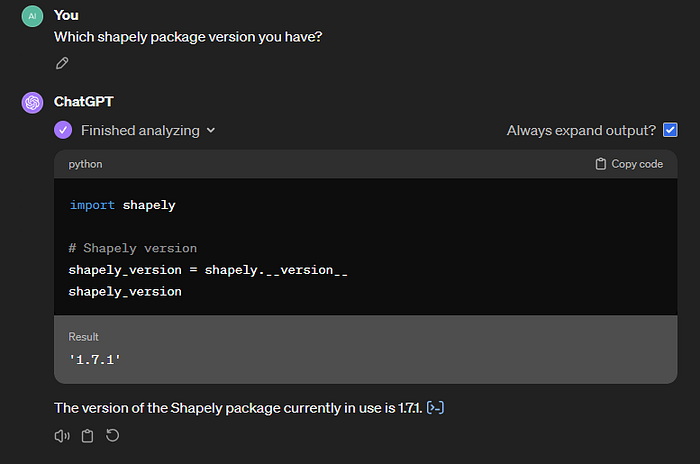
Which Python version are you using and list versions of Python packages that you have been imported?
Datu analīzē ChatGPT izmantoja sekojošas Python pakotņu versijas:

ChatGPT ģenerētie kodi ir pieejami arī GitHub.
Secinājumi
- ChatGPT 4 spēj identificēt kļūdas Python koda izpildē un tās labot, ja kļūdas ir vienkārši identificējamas un labojamas. Kļūdas, kas rodas Python pakotņu nesaderības dēļ, rīks labot nespēj.
- Pirms datu augšuplādes ieteicams tos apstrādāt tā, lai ChatGPT nav jāsaskarās ar Python kļūdām, vai arī uzvednē minēt iespējamos riskus ar ko rīkam varētu nākties saskarties. Tādā veidā tiktu paātrināta datu analīze. Jo sarežģītāki datu modificēšanas kritēriji, jo lielāka iespējamība, ka rīks šādu kritēriju saprot citādāk.
- Ja datu modificēšanu un pēc tam šo datu analīzi vēlaties veikt ar ChatGPT palīdzību, tad iesaku datu izmaiņas un datu analīzi veikt atsevišķās sesijās. Vienā — palūgt veikt nepieciešamās izmaiņas failā, otrā — veikt datu analīzi.
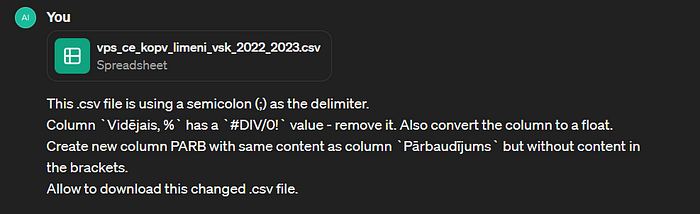
- Rīks neizprot sakarības starp kolonnām, tāpēc uzvednē būtu jāpiemin būtiskas kopsakarības, kas ir svarīgas datu analīzē (piemēram, vidējais aprēķins ir jāsver ar kolonnu X u.tml.).
- ChatGPT saprot uzvednes latviešu valodā, taču pievērsiet uzmanību sarežģītākām valodas konstrukcijām. Rīks tās varētu nesaprast.
- Vienā uzvednē var nodefinēt visas datu analītikas prasības, taču ir jāstrādā pie uzvedņu precīza formulējuma. Vērtējot pēc patērētā laika uzvedņu definēšanā, veidot vairākas mazākas uzvednes šajā eksperimentā bija labākais risinājums nekā aprakstīt vienu lielu uzvedni.
- ChatGPT 4 lietotājam ir jāsaprot Python kods, jo visi datu analīzes aprēķini veidoti ar šīs programmēšanas valodas palīdzību. Lietotājs, kurš nepārzin Python, var nepamanīt gadījumus, kad rīks iedod rezultātu, bet datu atlase neatbilst nosacījumiem.
- Ja nevēlaties ChatGPT ģenerēto kodu izpildīt vēlreiz, tad iesaku rīkā izveidotos grafikus saglabāt — pēc sesijas beigām attēli varētu nebūt vairs pieejami.
Oriģinālais raksts publicēts šeit.